

-
Informatique
www.indg.fr
-
Prestation de services en informatique
et réalisation de Sites Internet
25 ans d'expertise en informatique
Recherche
(Consultant indépendant en référencement)
Moteur de recherche
L'origine d'internet remonte à l'époque de la guerre froide. En 1964, les militaires américains auraient voulu avoir un système de communications à l'abri de toute attaque surprise, c'est-à-dire décentralisé et pouvant résister à la coupure " accidentelle " de telle ou telle liaison entre certains points de leur territoire. Le but était que l'on puisse utiliser un seul terminal pour se connecter à un nombre quelconque d'ordinateurs. Le concept d'internet fut finalement créé en 1973.
Les premiers moteurs de recherche apparaissent de 1990 à 1993. L'un des premiers d'entre eux Archie (10 septembre 1990), développé par quatre étudiants canadiens de l'Université McGill (Québec) : Peter J. Deutsch, Alan Emtage, Bill Heelan et Mike Parker. Il s'agit d'un moteur de recherche FTP.
A partir de 1993, des robots commencent à circuler sur le WEB. C'est Matthew Gray qui est à l'origine des premiers spiders qui se déplacent automatiquement sur toute la toile permettant d'en mesurer la taille. Le moteur de recherche de Matthew Gray s'appelle Wanderer et il est au http ce qu'Archie était au FTP.
Fondé sous le nom d'Architext en 1994 par Graham Spencer, Joe Kraus, Mark Van Haren, Ryan McIntyre, Ben Lutch et Martin Reinfried, Excite créé la rupture dans le monde de la recherche. En juillet 1994, le groupe d'étudiants reçoit la somme de 100 000 dollars de la société International Data Group pour la construction de ce moteur..
Suivent ensuite la naissance des grands moteurs de recherche tels que Lycos, Hotbot et Altavista. Apparu en décembre 1995, Altavista est l'oeuvre de Digital Equipment. Il est le premier moteur de recherche à indexer le maximum de pages webs. Il sera le moteur le plus utilisé jusqu'à l'arrivée de Google au début des années 2000.
D'autres sites en parlent
La recherche sur internet prend aujourd'hui de nouvelles dimensions avec l'utilisation de la géolocalisation.
Fonctionnement des moteurs de recherche
Quand la plupart des gens parlent de moteurs de recherche sur Internet,
ils ne considèrent que l'interface où ils vont saisir
leur requête et ensuite les pages de résultats
affichées par le moteur. Mais ceci n'est que le sommet de
l'iceberg et derrière se cache toute une mécanique
complexe que beaucoup n'ont même jamais imaginé.
A l'origine, internet n'est qu'un système de partage de
l'information qui se trouve stockée sur différents
serveurs disséminés dans le monde et ces informations et
documents sont reliés entre-eux par un système de liens
hypertexte. Depuis très longtemps il existait des moteurs de
recherche qui ont été mis en place pour aider les gens
à retrouver l'information sur le net. Des programmes du nom de
"gopher" et "Archie" conservaient un index des fichiers stockés
sur les serveurs connectés à l'Internet, et ont permis de
considérablement réduire le temps nécessaire pour
trouver des programmes et des documents spécifiques.
Aujourd'hui, la plupart des utilisateurs d'Internet utilisent un moteur
de recherche évolué tel que Google. Mais que ce
cache-t-il derrière cette interface sobre qui nous fournit
toutes les réponses à nos questions ? Etudions un peu en
détail le fonctionnement d'un moteur de recherche et se qui se
cache derrière.
Pour qu'un moteur de recherche puisse vous dire où un fichier ou
un document se trouve, il doit d'abord le trouver. Pour trouver les
informations sur les centaines de millions de pages Web qui existent,
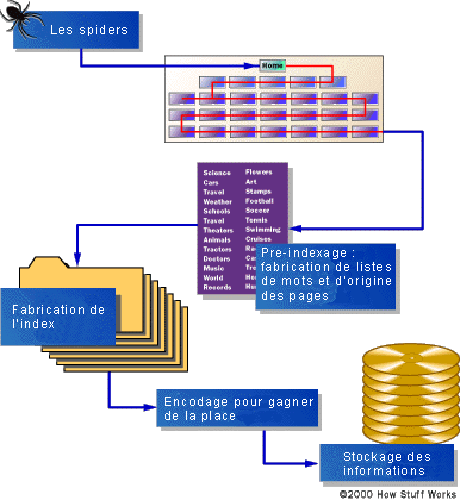
un moteur de recherche utilise des robots logiciels spéciaux,
appelés spiders. Ces robots parcourent continuellement le web
à la manière d'une araignée sur sa toile et
aspirent tout ce qu'ils trouvent pour construire des listes de mots
clés trouvés sur des sites Web afin de faciliter
l'indexation de toutes ces pages et documents. Quand les spiders
construisent ces listes, le processus est appelé Web ramper. En
plus des mots clés trouvés sur une page, le spider doit
également constituer une liste de liens afin de poursuivre son
chemin vers de nouveaux sites et ne pas tourner en rond sur les
quelques sites qu'il connait déjà. Cette liste de liens
sera ensuite exploitée afin de revenir
régulièrement voir les pages qui ont été
précédemment trouvées. Tout un système de
hiérarchie est construit afin que les spiders ne perdent pas de
temps à revenir voir sans cesse des pages qui ne changent
jamais. Ainsi, une page qui évolue sans cesse aura la visite de
plusieurs centaines de spiders par jour alors que pour les pages
oubliées au fond du web, elles n'auront droit à son passage que
tous les deux mois ou encore moins souvent.
Comment les spiders commencent leur voyage sur le Web ?
Les points de départ habituels sont des listes de serveurs
très utilisés et les pages très populaires.
L'araignée va commencer avec un site populaire, l'indexation des
mots sur ses pages et de chaque lien trouvé sur le site. De
cette manière, le système de crawl commence rapidement
à se déplacer, et à se diffuser à travers
les parties les plus utilisées du Web.
Google a commencé comme un moteur de recherche
académique. Dans le document qui décrit comment le
système a été construit, Sergey Brin et Lawrence
page donnent un exemple de la façon dont leurs spiders peuvent
travailler rapidement. Ils ont construit leur système initial
à partir de plusieurs spiders, habituellement de trois à
la fois. Chaque spider pouvait garder environ 300 connexions vers des
pages Web ouvertes à la fois. Lors de sa performance de pointe,
en utilisant quatre spiders, leur système pouvait explorer plus
de 100 pages par seconde, générant environ 600
kilo-octets de données par seconde.
Pour rester opérationnel il fallait construire un système
d'information nécessaire pour nourrir les araignées. Le
système Google à ses début avait un serveur
dédié pour fournir des URL aux spiders. Plutôt que
de dépendre d'un fournisseur de services Internet pour le
serveur de nom de domaine (DNS) qui traduit le nom d'un serveur dans
une adresse, Google avait son propre DNS afin de réduire au
minimum les temps d'accès.
Lorsque le spider de Google regardait une page HTML, il prenait note de
deux choses :
 Les mots dans la page
Les mots dans la page
Où les mots se trouvaient dans la page
Les mots peuvent apparaitre dans le titre, les sous-titres, les balises
meta et d'autres positions d'importance relative. Chaque position
était notée d'une attention particulière pour les
recherches utilisateur ultérieures. Les spiders de Google
construisaient un index de chaque mot significatif de la page, en
laissant de côté les articles « un », «
une » et « la ».
D'autres spiders ont des approches différentes
Ces différentes approches tentent généralement de
faire en sorte que le spider fonctionne plus rapidement, permettent aux
utilisateurs de rechercher plus efficacement, ou les deux. Par exemple,
certains spiders gardent trace des mots dans le titre, sous-rubriques
et les liens, avec les 100 mots les plus fréquemment
utilisés sur la page et chaque mot dans les 20 premières
lignes de texte. Lycos utilisait cette approche pour parcourir le Web.
D'autres systèmes, comme AltaVista, vont dans l'autre sens,
l'indexation de chaque mot sur une page, y compris les articles et
d'autres termes « insignifiants ». La poussée
à l'exhaustivité de cette approche est compensée
par d'autres systèmes tel qu'accorder l'attention à la
partie invisible de la page Web, les balises meta.
L'indexation
L'ensemble des pages accédées par les spiders et pré-indexées par ceux-ci doit ensuite être digéré par un système d'indexation dans des bases de données afin d'en permettre l'accès aux utilisateurs. Il existe tout un système complexe afin de donner plus ou moins d'importances à certaines pages pour que les résultats de recherche soient le plus pertinents possibles par rapport à une requête. Google ajoute ensuite des filtres pour pénaliser les sites qui essayent de tricher en bourrant leurs pages de mots clés qui n'ont rien à voir avec le contenu de la page, simplement pour être référencés sur ces mots clés très utilisés. Ces filtres se sont industrialisés avec l'arrivée de Panda et Penguin qui sont des algorithmes pour lutter contre le spam du web et le black SEO (tentative de détournement des systèmes d'indexation des moteurs de recherche pour être mieux positionné que ses concurrents).
Le stockage des informations
Le système de bases de données d'informations d'un moteur de recherche est ensuite encodé pour gagner de la place et stocké sur des disques durs.
La recherche proprement dite
Quand on accède à la page de recherche d'un moteur de recherche et qu'on saisit une requête, c'est une autre partie du moteur de recherche qui fonctionne. Cet algorithme est chargé d'accéder aux informations stockées en base de données pour retrouver toutes les pages qui correspondent à votre requête et il utilise ensuite des centaines de critères pour classer ces pages entre-elles afin de faire apparaitre en premier les pages les plus pertinentes par rapport à votre demande. L'ordre des pages dans les résultats de recherche s'appelle le positionnement. C'est le sommet de l'iceberg. Une science est née à partir de là. On l'appelle Search Engin Optimization ou SEO. C'est l'art d'améliorer le positionnement d'un site dans les résultats de recherche.