



-
Informatique
www.indg.fr
-
Informatique de gestion grandes entreprises
Expert COBOL PACBASE DB2
25 ans d'expertise en informatique
Méthode
CORIG
(Concepteur d'applications sur gros système)
Les principes de CORIG
Mes deux ans d'études à l'I.U.T. informatique de Bourgogne se sont terminés par un stage de trois mois en entreprise. En 1988, j'ai effectué ce stage au service Bases de Données du Crédit Mutuel de Bourgogne-Champagne à Dijon.
Le système de bases de données utilisé par cette banque était de type IDMS Codasyl-Réseau. Il s'agit d'une représentation des données sous forme d'un réseau de fichiers dans lequel certaines données sont « parents » et d'autres « enfants ». Pour accéder au solde d'un compte il faut commencer par accéder à la donnée « agence », puis « client » qui sera une de ses données « filles » et ensuite à la donnée « compte » qui est elle même « fille » de « client ». Au passage sur chaque entité, des pointeurs sont récupérés afin d'accéder de façon optimum aux fichiers enfants ou parents mais pour accéder à quelque donnée que ce soit il faut en connaître le chemin exact ce qui rend la programmation dépendante de la structure des données.
C'est au cours de ce stage en entreprise que j'ai appris une nouvelle méthode de programmation qui me servira énormément par la suite. Il s'agit de la méthode CORIG. On verra que CORIG constitue la base fondamentale de l'AGL PACBASE avec lequel je travaille depuis 1994.
Les principes de CORIG sont simples : il s'agit d'une écriture linéaire des programmes. Ceux-ci sont découpés en sous-fonctions comme avec la méthode des arbres programmatiques mais au lieu d'avoir au début de la partie « instructions » du programme l'appel de chaque sous-fonction de façon hiérarchique (en suivant les niveaux d'imbrications déterminés par la représentation de l'arbre), toutes les sous-fonctions sont écrites en série sous forme de « briques » fonctionnelles. La brique fonctionnelle est constituée de trois parties disctinctes :
- une condition d'exécution
- la sous-fonction proprement dite
- le label de fin de l'unité fonctionnelle.
En premier lieu c'est la condition d'exécution qui est testée. Si la condition est remplie le programme se poursuit en séquence par l'intermédiaire de l'instruction COBOL next sentence. Dans le cas où la condition n'est pas vérifiée le programme effectue un saut jusqu'à la fin de l'unité fonctionnelle. Il est très important que ce saut s'effectue à la fin de l'unité courante et non au début de l'unité fonctionnelle suivante car ceci permet que chaque brique fonctionnelle soit indépendante des autres. Cela facilite grandement la maintenabilité des programmes car on peut reprendre une sous-fonction existante dans un programme pour l'inclure facilement dans un autre ou bien déplacer facilement des sous-fonctions pour les faire s'exécuter dans des ordres différents. Avec la méthode des arbres programmatiques il faut revoir lors de chaque maintenance la structure de l'arbre et il est très mal aisé de modifier un programme sans avoir le schéma représentatif de l'arbre sous les yeux. On doit le refaire à chaque fois si un minimum de documentation n'est pas maintenu. Avec la méthode CORIG tout programme se lit de haut en bas et la dernière instruction d'un programme consiste à effectuer un saut (instruction cobol go to) au début du cycle. Le cycle CORIG commence en général par la lecture du fichier principal (fichier maître).
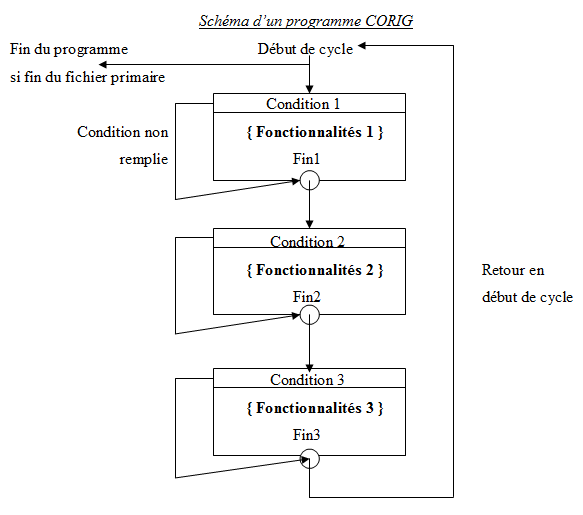
Ce principe de cycle se retrouve également dans le langage GAP, c'est ce
qu'on appelle le « cycle GAP ». Et il est bien entendu
présent dans PACBASE et forme le coeur de sa structuration.
Au niveau coding voici comment ça se passe :
... (c'est ici qu'on place tous les traitements à ne faire qu'une seule fois)
DEBUT-CYCLE.
READ FICIN AT END MOVE HIGH-VALUE TO ENR-FICIN.
FIN-PROGRAMME.
IF ENR-FICIN = HIGH-VALUE
CLOSE FICIN
STOP RUN.
END-IF.
FONCTION1.
IF xxxxx = xxxxxx (on met la condition de la fonction 1)
NEXT SENTENCE
ELSE
GO TO F-FONCTION1.
...
insérer les traitements correspondants à la fonction 1
...
F-FONCTION1.
EXIT.
FONCTION2.
IF xxxxx = xxxxxx (on met la condition de la fonction 2)
NEXT SENTENCE
ELSE
GO TO F-FONCTION2.
...
insérer les traitements correspondants à la fonction 2
...
F-FONCTION2.
EXIT.
FONCTION3.
IF xxxxx = xxxxxx (on met la condition de la fonction 3)
NEXT SENTENCE
ELSE
GO TO F-FONCTION3.
...
insérer les traitements correspondants à la fonction 3
...
F-FONCTION3.
EXIT.
FIN-CYCLE.
GO TO DEBUT-CYCLE.
Comme vous le voyez le programme est absolument linéaire, il se lit de haut en bas. Chaque fonction est indépendante. Il est absolument interdit d'effectuer un GO TO pour sortir de la fonction en cours autrement que par le paragraphe F-FONCTION.
Une fonction CORIG peut elle-même être décomposée en sous-fonctions qui seront elles aussi conformes à la méthode de programmation CORIG. Elles seront imbriquées dans une fonction et possèderons toutes une partie conditionnement et une partie traitement.
L'utilisation de cette méthode facilite beaucoup la lisibilité et la maintenance des programmes.